Google Docs にテキストを OCR する機能が追加予定?

Perform OCR with Google Docs – Turn Images Into Editable Documents
まだユーザーインターフェースそのものに組み込まれてはいないようですが、Google Docs に OCR 機能が追加されるのではないかという記事が Digital Inspiration で紹介されています。
この機能は Document List Data API の例として公開されているもので、こちらのフォームを利用して画像をアップロードすると、テキストが認識されて自動的に Google Documents に変換されます。
-
現在の所英数字のみ
-
画像はそれなりに高解像度の必要があります。1文字ごとに 10 px ほどの高さが目安
-
ファイルサイズは最大 10 MB、25 メガピクセル
-
ファイルサイズに従って時間がかかります。500K くらいなら 15 秒、2M なら 40 秒、10MB なら果てしなく時間がかかるとのこと
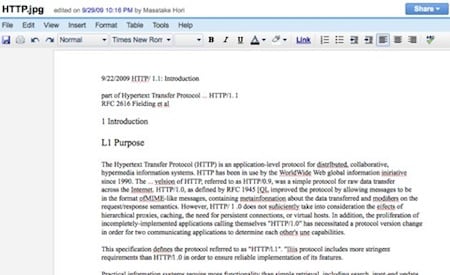
実際おいてある 600 KB の例を使ってみたところ、問題なく読み込むことができました。
「情報を飲み込みすぎだ」という批判が多い Google ですが、こうした、これまでデジタル化できていなかった過去の情報も利用可能になってゆくのは個人的には歓迎しています。
つい先日も、大学時代の若書きの原稿用紙数百枚をスキャンしたところですが、もしこれを自動的にデジタルにできるなら数万円をはらっても惜しくはありません。
また自分の本棚からも次々と本をデジタル化して iPhone に入れて読んだりしていますが、こうした場所取りなモノを捨てて情報そのものは捨てない、というスタイルは当面の情報過多をしのぐのに不可欠の手法です。
まさかスキャンしたドキュメントが自動的に Google Books のアーカイブに登録されてゆくというブラックジョークはないと思いますので、利用したい手書きのリソースが手元にある人は利用してみてはいかがでしょう。